출처: KQTI
오늘은 기본적인 데이터의 종류에 대해서 알아보도록 하겠습니다.
데이터의 종류를 알아보는 것은 데이터 수집시 어떤 유형으로 수집하는 것이 좋은지를 설정하는 것부터 분석이나 시각화를 하는 것까지 데이터 유형에 따라 달라지므로 할 수 있는 것이 있고, 없는 것도 있습니다. 따라서 구분 할 수 있는 것이 상당히 중요하겠죠?
데이터 분석과 시각화의 관점에서 봤을 때 중요한 데이터 유형은 크게 두가지로 나눌 수 있습니다.

크게는 범주형과 수치형으로 나뉘게 되고 세부적으로는 범주형은 명목형과 순서형, 수치형은 이산형과 연속형으로 나뉘게 됩니다. 개별로 한번 알아볼까요?
첫째, 명목형 데이터 (Nominal Data)
명목형 데이터는 Nominal 이라는 이름에서도 알 수 있듯 여러 카테고리들 중 하나의 이름에 데이터를 분류할 수 있을 때 사용됩니다.

명목형 데이터는 순서를 매길 수 없고 셀 수 있다라는 특징을 가지고 있습니다.
평균을 계산하는 것이 의미가 없고, 퍼센트로 표현이 가능합니다.
둘째, 순서형 데이터 (Ordinal Data)
순서형 데이터의 경우에는 말그대로 카테고리들이 순서가 있는 경우를 의미합니다.
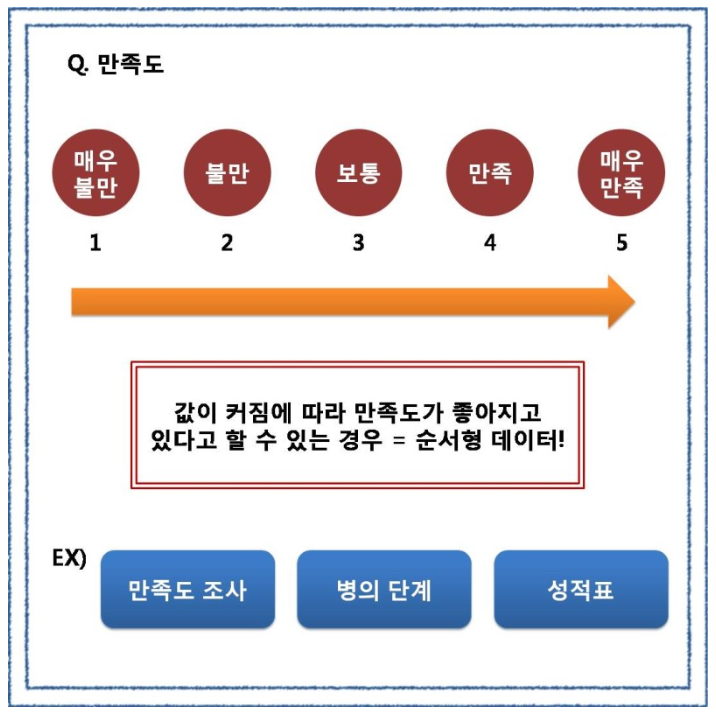
명목형 데이터와 같이 수를 세고 퍼센트로 표현할 수 있습니다.
리커트 척도는 5점 척도, 7점 척도 등을 통해 숫자로 표현되지 않는 것을 숫자로 표현해준다고 생각하시면 됩니다. 위의 예시 처럼 만족도를 5점 척도로 표현을 한다면 이는 리커트 척도를 이용한 것이죠,
특이하게도 리커트 척도는 등간격이라는 특징 때문에 연속적인 값을 가질 수 없더라도 평균을 구할 수 있습니다. 단, 주의하셔야 할 점은 이때 구해지는 평균이라는 숫자는 수학적인 의미가 있는 것이 아닙니다. 5점 척도를 이용하여 조사를 하고 구한 평균이 4.1 이라면 대다수의 사람들이 만족하고 있다고 볼 수 있다는 것입니다.
셋째, 이산형 데이터 (Discrete Data)
이산형 데이터는 수치적인 의미를 가지나 소수점의 형태로 표현되지 못하는 데이터를 의미합니다.
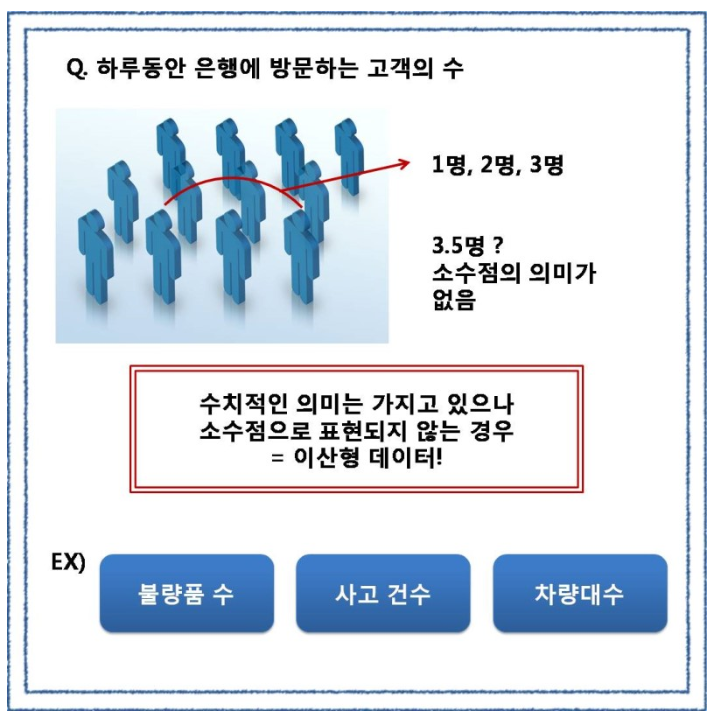
이산형 데이터의 표현방법으로는 앞선 데이터와 동일하게 퍼센트로 표현하며, 예를들어 불량품 수라고 한다면 '양산되는 제품들 중 불량률이 5%다.' 라고 할 수 있습니다.
넷째, 연속형 데이터 (Continuous Data)
연속형 데이터는 수치적인 의미를 가지고 소주점으로 표현이 가능하며, 측정할 수 있는 데이터를 의미합니다.

연속형 데이터의 경우에는 평균과 표준편차, 분산으로 표현하고 추가적으로 퍼센트로도 표현이 가능합니다. 예를들어 키를 보면 160, 170, 180의 사람이 있다면 평균은 170, 표준편차는 10이 됩니다.
이를 퍼센트로 하면 160~169, 170~179, 180~189 총 3개의 구간으로 나눠서 봤을 때 수를 세면 각 구간별로 하나씩 나옵니다. 따라서 퍼센트로 따지면 33.3%가 되는 것입니다.
예를들어 나이를 본다면, 여러가지의 데이터 형태로 구분지을 수 있습니다.
먼저 나이 그자체를 보면 우리는 시간의 흐름에 따라 나이를 자연스럽게 먹고 있기 때문에
연속형 데이터라고 할 수 있습니다.
하지만 20살~29살 까지인 사람들의 수를 센다면 이산형 데이터가 될 수 있겠죠.
그리고 설문조사시 연령을 묻는 문항에서 ① 10대 ② 20대 ③ 30대 ④ 40대 ⑤ 50대 이상 으로 데이터를 수집했다면 이는 순서형 데이터가 된다는 것이죠.
이처럼 동일하게 나이를 나타내는 데이터를 어떻게 수집하느냐에 따라서 데이터 유형이 달라집니다.
그리고 데이터 분석 방법도 달라지겠죠. 그러므로 데이터를 구분할 줄 아는 것이 중요합니다.
'IT기술 관련 > A.I 인공지능' 카테고리의 다른 글
| 문과생을 위한 딥러닝 수학 - 핵심편 (1) (0) | 2019.10.10 |
|---|---|
| 문과생을 위한 딥러닝 수학 - 기본편 (4) 절댓값 함수, 가우스 함수 (0) | 2019.10.09 |
| 문과생을 위한 딥러닝 수학 - 기본편 (3) 유리함수, 무리함수 (0) | 2019.10.08 |
| 선형관계, 비선형관계, 단조관계 알아보자 (0) | 2019.10.07 |
| 문과생을 위한 딥러닝 수학 - 기본편 (2) 지수함수, 로그함수 (0) | 2019.10.07 |