딥러닝이라는 말이 학계, 업계 어디든 할 것 없이 엄청난 화두이다. 그래도 아직까지는 기계학습이면 충분하지만 점점 더 인공지능과 관련된 신경망 기반의 딥러닝 알고리즘들에 대한 수요가 더욱 중요해질 것이다.(그것이 설령 필요하지 않더라도... 오버스펙...) 어쨌든 기계학습(machine learning) 알고리즘의 하나일 뿐인 딥러닝이 이제는 기계학습이라는 용어 자체를 대변하려는 기세를 보이고 있다. 기계학습에 대해 설명한 좋은 글들이 많이 있다. 간단하게 본다면 기계학습은 기계가 학습하는 것이다!(?) 컴퓨터는 인간에 비해서 복잡한 연산을 아주 빠르게 소화할 수 있는 기계일 뿐이었고 사람과 같이 무언가를 인식하는 것은 하지 못했다. 기계학습은 기계가 학습을 해서 인간처럼 사물도 인식하고 무언가를 분류해보고 묶어보고 하도록 하는 것이라고 보면 된다.
최근 기존 기계학습 방식으로는 처리가 어려운 문제를 딥러닝으로 해결해보려는 시도가 많아지고 있는 만큼 아직 기계학습(머신러닝)을 살펴보는 중이지만 딥러닝에 대해서도 본격적인 공부를 해보려고 한다.
1. 퍼셉트론 기초 개념
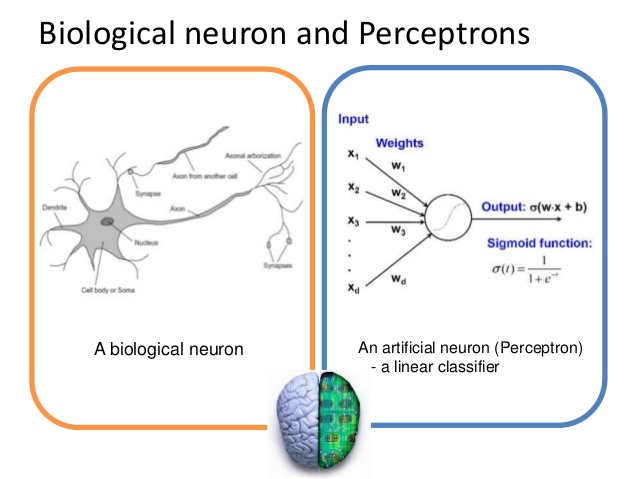
인공 신경망 모형의 하나인 퍼셉트론은 1957년에 Rosenblatt라는 사람에 의해서 처음 고안된 아주 오래된? 알고리즘이다. 일반적으로 인공 신경망 시스템은 동물의 신경계를 본따 만들었기 때문에 개념적으로나 그 형태로나 비슷한 부분이 많다. 아래 왼쪽의 뉴런(neuron) 그림은 생물을 공부해본 사람들은 모두 한 번쯤은 봤을 것이다. 생물심리학을 공부할 때 또 봤다...
퍼셉트론은 다수의 신호(Input)을 입력받아서 하나의 신호(Output)을 출력한다 이는 뉴런이 전기신호를 내보내 정보를 전달하는 것과 비슷해 보인다. 그리고 뉴런의 수상돌기나 축색돌기처럼 신호를 전달하는 역할을(정확한 말은 아니고 편의상 이렇게 설명... 용어가 아직도 기억이 나다니...) 퍼셉트론에서는 weight가 그 역할을 한다. 가중치라고 부르는 이 weight는 각각의 입력신호에 부여되어 입력신호와의 계산을 하고 신호의 총합이 정해진 임계값(θ; theta,세타)을 넘었을 때 1을 출력한다. (이를 뉴련의 활성화activation 으로도 표현) 넘지 못하면 0 또는 -1을 출력한다.
각 입력신호에는 고유한 weight가 부여되며 weight가 클수록 해당 신호가 중요하다고 볼 수 있다.
여기서 기계학습이 하는 일은 이 weight(입력을 조절하니 매개변수로도 볼 수 있음)의 값을 정하는 작업이라고 할 수 있다.학습 알고리즘에 따라 방식이 다를 뿐 이 weight를 만들어내는 것이 학습이라는 차원에서는 모두 같다고 할 수 있다.
퍼셉트론의 출력 값은 앞에서 말했듯이 1 또는 0(or -1)이기 때문에 선형 분류(linear classifier) 모형이라고도 볼 수 있다. 보통 실수형의 입력 벡터를 받아 이들의 선형조합을 계산하는 것이며 다른 포스팅에서 다룬 벡터의 내적과도 유사하다. 선형 분류는 저 아래 그림에서 어떤 것인지 보면 알 수 있는데 간단하게 설명하면 초등학교 때 옆에 앉은 짝꿍과 티격태격하다 책상 중간에 선을 쫙 긋고 "이 선을 넘으면 다 내거"라고 했던 기억이 한번쯤은 있을지도 모르겠다. 선형 분류는 이와 비슷하게 평면 상에 선을 쫙 그어서 여기 넘으면 A, 못 넘으면 B 이런식으로 분류하는 것이다.
2. 퍼셉트론 학습 방법
처음에는 임의로 설정된 weight로 시작한다.
학습 데이터를 퍼셉트론 모형에 입력하며 분류가 잘못됐을 때 weight를 개선해 나간다.
weight를 개선해 나간다는 의미는 우리가 수학 문제를 잘못 풀었을 때 선생님이 다시 풀어오라고 하면 정답에 맞게 풀기 위해서 다시 풀고 다시 풀고 하다가 정답을 맞추는 것과 비슷하다. 그래서 학습이라고 부른다. 이 학습이라는 말이 실제 우리가 생각하는 학습의 개념과 유사한 점이 많아 학습 심리학에서 공부했던 내용을 추후에 접목해서 따로 소개하고자 한다.
퍼셉트론은 모든 학습 데이터를 정확히 분류시킬 때까지 학습이 진행되기 때문에 학습 데이터가 선형적으로 분리될 수 있을 때 적합한 알고리즘이다. 이와 관련된 퍼셉트론 모형이 가지는 한계는 후에 설명하겠다. 선형분류는 아래와 같이 선으로 분류하는 것을 의미한다. 학습이 반복될수록 선의 기울기가 달라지는 것을 볼 수 있다. 학습을 하면서 weight가 계속 조정(adjust)되는 것이다.
과 같이 되며 여기에서 b를 편향(bias)라고 할 수 있다. 기계학습 분야에서는 모델이 학습 데이터에 과적합(overfitting)되는 것을 방지하는 것이 중요하다. 여기서 과적합이라 함은 모델이 엄청 유연해서 학습 데이터는 귀신같이 잘 분류하지만, 다른 데이터를 넣어봤을 때는 제대로 성능을 발휘하지 못하는 것을 말한다. 어느 데이터를 넣어도 일반적으로 잘 들어맞는 모델을 만드는 것이 중요하다.
따라서 앞에서 설명했듯이 편향은 θ(theta)로 학습 데이터(Input)이 가중치와 계산되어 넘어야 하는 임계점으로 이 값이 높으면 높을 수록 그만큼 분류의 기준이 엄격하다는 것을 의미한다. 그래서 편향이 높을 수록 모델이 간단해지는 경향이 있으며 (변수가 적고 더 일반화 되는 경우) 오히려 과소적합(underfitting)의 위험이 발생하게 된다. 반대로 편향이 낮을수록 한계점이 낮아 데이터의 허용범위가 넓어지는 만큼 학습 데이터에만 잘 들어맞는 모델이 만들어질 수 있으며 모델이 더욱 복잡해질 것이다. 허용범위가 넓어지는 만큼 필요 없는 노이즈가 포함될 가능성도 높다. 이를 편향과 분산의 트레이드오프 관계라고 보통 부르며 기회가 되면 이 부분을 더 다뤄보도록 하겠다. (포스팅 추가)
쉽게 예를 들어 '다문화'와 연결해서도 생각해 볼 수 있을 것 같다. 정확한 의미는 다르지만 유럽에서는 경제성장을 위해서 다국적의 사람들의 이민을 쉽게 허용해주었고 그들의 고급 노동력뿐만 아니라 그 아래 노동력도 포함해서 많은 인력을 수급하였다. 그 결과 경제성장의 밑거름이 되었다. ( + ; 학습한 모델이 잘 들어맞는 상황) 하지만, 다문화의 차이로 인한 갈등, 범죄율 상승 등의 문제가 발생하였다. ( - 손해; overfitting) 그렇다고 이민정책을 엄격하게 잡으면 사람들을 적게 받아 큰 플러스 효과를 보지 못할 수 있다. (- 손해; underfitting)
위의 예시는 적절하다고 볼 수는 없으나 결국 그 핵심은 학습의 과정에서 불순물(Noise)가 얼마나 포함되고 이것을 잘 걸러내줄 수 있느냐가 관건임을 말하고 싶었던 것이다.
요약하면, 가중치(weight)는 입력신호가 결과 출력에 주는 영향도를 조절하는 매개변수이고, 편향(bias)은 뉴런(또는 노드; x를 의미)이 얼마나 쉽게 활성화(1로 출력; activation)되느냐를 조정하는(adjust) 매개변수이다.
4. 퍼셉트론의 한계점
하지만 퍼셉트론이 인공지능 분야에서 센세이션을 불러일으켰고 연구 과제도 이쪽으로 몰렸으나 이것이 가지는 한계점이 밝혀지면서 한동안 소외 받는 이론이 되었다. 퍼셉트론을 제시한 로젠블랫은 자살 같은 사고로 세상을 떠났고 시간이 흐른 뒤에야 그의 업적이 재조명 받았다. 퍼셉트론의 한계는 선형으로 분류를 할 수 있지만 XOR와 같이 선형 분류만 가능하며 비선형 분류는 불가능하다는 점이다.
XOR 논리는 exclusive(배타적) 논리연산이다. 아래의 진리표를 보면, x1과 x2 중 어느 한쪽이 1일 때만 1을 출력한다.
x1
x2
y
0
0
0
1
0
1
0
1
1
1
1
0
아래의 그림을 보면 XOR에서는 선형으로(직선 하나로) 분류가 불가능함을 알 수 있습니다.
퍼셉트론의 한계를 간략히 말하면, 직선 하나로 나눈 영역만 표현할 수 있어 XOR과 같은 데이터 형태는 분류가 불가능하다는 한계가 있다.
5. 다층 퍼셉트론을 통한 한계 극복
단일 퍼셉트론으로는 XOR을 분류할 수 없지만, 다층 퍼셉트론을 만들면 이를 극복할 수 있습니다. 다층(multi-layer)이라는 말은 하나의 퍼셉트론에 또 다른 퍼셉트론을 덧붙인다는 의미로 볼 수 있다. 단층 퍼셉트론이 비선형 영역을 분리할 수 없다는 것이 문제이며 다층으로 할 경우 비선형으로 이를 해결할 수 있다.
그동안의 바쁜 일정으로 인해서 2달 만에 포스팅을 하게 되었습니다... 다른 카테고리의 글들도 업데이트를 해야 하나 우선 가장 급하다고 생각하는 '수학'에 대해서 먼저 다루려고 합니다.
기초편에서도 말했듯이 데이터를 분석하거나 머신러닝, 딥러닝을 하기 위해서는 약간의 수학적 개념만 알아도 충분히 할 수 있지만 실무 프로젝트와 학업을 진행하면서 느낀 점은 수학적인 뒷밤침이 없다면 단순히 코드만 돌리고 결과만 확인하게 된다는 것입니다. 이는 모래 위에 쌓은 성과 같은 '사상누각'이라고 할 수 있습니다. 데이터 과학의 대부분은 우리 주변의 문제 'What'을 해결하고자 하지만 우리가 수행한 'How'에 대한 'Why'가 충분히 뒷받침 되지 않는다면 결과의 정확도나 해석의 타당성이 떨어집니다. 또 어떤 예측 모형을 구축한다고 했을 때 그 과정에서 발생하는 문제를 적절하게 해소하지 못할 수 있습니다.
그렇다면 수학을 왕창 다 배워야 하느냐? 그건 아닌 것 같습니다. 선형대수와 행렬 미분 정도만 그 기본 개념을 제대로 짚고 넘어간다면 충분하다는 생각을 했습니다. 딥러닝은 벡터의 연산 집합이라고도 할 수 있습니다. 그 유명한 PCA도 벡터 연산이 중심입니다.
최근 Coursera에서 Mathematics for Machine Learning이라는 Specialization을 오픈했습니다. 딱! 제가 필요로 하던 수학만 학습할 수 있도록 준비되어 있습니다. 제 스스로도 너무 오랫동안 수학을 안했고 필요성을 느껴 필요한 것만 되짚어 보기 위해, 다시 공부하기 위해 위 강의를 수강하며 들은 내용들을 정리하려고 합니다.
Linear Algebra
Matrix Calculus
PCA
세 과목에 대해서 다룰 예정이고 각 과목의 핵심 포인트는 앞으로 다루면서 다룰 예정입니다. 먼저 선형대수를 하려고 합니다. Coursera에서는 Beginner 과정으로 선행 지식이 필요없다고 하지만 기초적인 수식에 대한 이해와 배경지식을 필요로 합니다. 따라서 만약 저와 같이 문과 출신으로 수학적 배경이 전무하신 분들은 아래에 소개한 이전 포스트들을 먼저 읽으시면 좋을 것 같습니다.
대부분의 현실 세계의 문제를 해결하기 위해서 우리는 시스템을 만들고 어떤 모형을 만듭니다. 일명 머신러닝이라는 방법으로 구축하는 추상화된 수학적 모형을 통해서 예측을 하거나 분류를 하거나 합니다. 그런데 데이터 분석을 하고자 하는 저와 같은 사람들에게 엄청난 장벽이 있습니다. 바로 수학입니다... 대부분의 자료나 강의들은 우리가 당연히 수학이나 컴퓨터과학적인 지식이 있다고 가정하고(강의마다 이 가정의 편차가 극심합니다...) 진행되기 때문에 겉핥기로도 공부하기가 굉장히 힘듭니다.
이 수학적 모형이라는 것이 결국 벡터(Vector), 벡터 공간(Vector Space)으로 표현(representation)되며 대부분의 연산(operation)은 이러한 벡터 공간들간의 연결(mapping)을 통해서 이루어지기 때문에 가장 먼저 이를 다루는 선형대수를 알아야 합니다. 유명한 구글의 Page Rank는 이러한 벡터, 행렬 연산을 통해 만든 하나의 예시입니다.
행렬 연산은 우리가 아는 연립방정식에서도 발견할 수 있습니다. 연립방정식은 문과생을 위한 수학 기본편에서 확인하실 수 있습니다. 어쨌든 2x + 3y = 8 이라는 방정식과 3x + 2y = 7이라는 두 방정식을 통해서 우리는 x와 y의 값을 구할 수 있습니다. 머신러닝에서 fitting한다는 것은 이 x와 y를 찾아가는 것이라고도 할 수 있습니다. coursera 강의에서 연립방정식에 대해 이해하고 있는지 먼저 테스트를 하였습니다.
Python으로 아래의 test 문제를 풀 때는 NumPy의 linalg.solve 메소드를 사용하여 연립방정식의 해를 구할 수 있습니다.
5x - 2y = -13
4x +5y = -6
In [1]: import numpy as np
In [2]: a = np.array([[5,-2],[4,5]])
In [3]: b = np.array([-13, -6])
In [4]: x = np.linalg.solve(a, b)
In [5]: x
Out[5]: array([-2.33333333, 0.66666667])
아래의 분포 그래프는 사람들의 신장(height)에 대한 히스토그램을 분포 그래프로 표현한 것입니다. 신장이 큰 사람부터 작은 사람까지 정규분포 모양으로 모집단(population)이 존재할 지 모릅니다. f(x)은 신장에 대한 분포를 표현한 함수로 μ와 σ 두 개의 파라미터로 구성 되어 있습니다. 이 파라미터를 적합(fitting)시켜서 모집단에 대한 적절한 분포를 찾아갈 수 있습니다. μ가 움직인다면 분포 전체가 왼쪽, 오른쪽으로 이동할 것이고, σ가 변한다면 분포의 종모양이 얇게 올라가거나 또는 평평하게 내려 앉을 수 있습니다.
오른쪽의 등고선 모양은 μ와 σ 두 개의 파라미터가 존재할 수 있는 영역을 표시한 것이고 이 값을 변화시키면서 최적의 파라미터 값을 찾아나가게 됩니다.(value of goodness) 이렇게 실제로 표현/추정하기 위해 파라미터를 적합하는 것은 머신러닝을 아는 이들에게는 많이 익숙한 개념입니다. 벡터는 이를 도와줍니다. 단순히 Physics에서만 다루어지는 것이 아닌 우리의 현실 세계에 대해서 표현하는 방법이 되고 우리는 이를 통해 많은 문제를 해결해볼 수 있습니다.
다음은 벡터에 대한 정의입니다.
2. 벡터(vector)의 정의
1) A list of numbers
- 컴퓨터에서 보듯이 단순히 일련의 숫자 리스트로 볼 수 있고, 숫자이기때문에 연산이 가능한 것
Vectors are usually viewed by computers as an ordered list of numbers which they can perform "operations" on - some operations are very natural and, as we will see, very useful!
2) Position in three dimensions of space and in one dimension of time
- 아이슈타인은 '시간(time)'도 하나의 차원(dimension)이라고 했다. 3차원의 우리 세계에 시간이라는 차원이 추가된 4차원으로 세상을 볼 수 있다.
A vector in space-time can be described using 3 dimensions of space and 1 dimension of time according to some co-ordinate system.
3) Something which moves in a space of fitting parameters
- 이 모든 것은 벡터 공간(vector space)로 표현이 가능하고 벡터공간 안에서 값을 변경해가며 파라미터 최적화를 통해 우리가 얻고 싶은 solution을 얻을 수도 있다.
As we will see, vectors can be viewed as a list of numbers which describes some optimisation problem.
3. 벡터 연산 Vector Operation
벡터는 크기와 방향을 가지고 있습니다. 어떤 벡터 공간 안에서 이것이 표현 가능하며 머신러닝에서는 보통 위에서 다룬 연립방정식에서처럼 벡터로 만들고 벡터 공간안에서 적절한 parameter를 찾기 위해 fitting하는 과정을 갖습니다. parameter를 최적화하는 과정이 Vector Space에서 크기와 방향을 바꿔가면서 움직이는 것과 같으며 사람이 조금씩 수정하면서 찾는 것이 아닌 알고리즘을 통해 자동적으로 최적의 해를 찾아가는 것이 차이입니다.
3.1 벡터의 합연산은 순서와 관계가 없다
3.2 벡터의 스칼라(넘버) 곱연산은 scalar 만큼 반복하는 것이고 -(minus)는 반대로 방향이 바뀐다
3.3 벡터는 크기(size/length)와 방향(direction)을 가졌다.
벡터의 크기와 방향을 표현할 때는
이렇게 계산해서 구할 수 있다. 피타고라스 정리를 사용한 것입니다.
# Simple Python code for Calculation of vector size
In [1]: import numpy as np
In [2]: a = np.array([1, 3, 4, 2])
In [3]: size_of_a = np.sqrt(np.sum(np.square(a)))
In [4]: size_of_a
Out[4]: 5.4772255750516612
3.4 Dot Product ★★★
무슨무슨 법칙으로 보통 설명하지만 쉬운 이해를 위해서 풀어서 설명합니다. 아래는 벡터 내적의 법칙입니다.
1) commutative : 순서를 바꿔도 결과는 동일합니다. rs=sr
2) distributive : 괄호 안의 벡터를 풀어서 계산할 수 있습니다. r(s+t) = rs+rt
3) associative : 순서가 상관이 없기 때문에 결합이 자유롭게 됩니다. r(as) = a(rs), r(iasi)+rj(asj) = a(risi+rjsj)
# Simple Python code for dot product
In [1]: import numpy as np
In [2]: a = np.array([-5, 3, 2, 8])
In [3]: b = np.array([1, 2, -1, 0])
In [4]: np.dot(a, b)
Out[4]: -1
Dot Product : Its simply the projection of one vector onto the other multiplied by the magnitude of other vector . The dot product tells you what amount of one vector goes in the direction of another (Thus its a scalar ) and hence do not have any direction .
a.b= ||a|| ||b|| cos(θ). Alternatively if a=(x1,y1) and b=(x2,y2) (Position vectors) the dot product is x1.x2+y1.y2 .
3.5 Cosine Rule을 벡터로 바꾸어봅시다
삼각형의 세 변 a, b, c는 벡터 r, s. r-s로 표현됩니다. 각도는 θ입니다. 코사인 법칙
을 벡터로 바꾸면
가 됩니다. cos 90도 일때는 이 값이 0이 되므로 rs=0이 되고 아래의 그림처럼 직각인 상태에서는 전체가 0이 됩니다. cos 0도일 때는 그 값이 1이며 rs=1이 됩니다. 이 때는 r과 s 벡터가 같은 방향을 가집니다.
이미 딥러닝을 공부하신 분들은 아시는 내용이지만 cos 90도로 벡터 간 각도가 90인 것은 벡터가 서로 직교(Orthogonal)함을 의미합니다. 다른 딥러닝 포스팅에서도 이 내용을 다루었습니다. one-hot encoding 방식은 벡터간의 내적이 0이 되므로 interaction이 고려되지 않음을 말하고 그래서 확률적 표현(probabilistic representation)을 통해 이를 극복하고자 하기도 하였습니다.
직교한다는건 서로 만날 일도 없고 연관되지 않는다고도 볼 수 있는데 방금 증명하였듯이 90도일 때는 두 벡터의 내적(dot product)이 0이 되기 때문에 이를 뒷받침해줍니다. 직교에 대한 자세한 내용은 이후에 더 다룰 것으로 보입니다. cosine 180도라면 -1이므로 두 벡터간의 관계가 반대방향으로 될 것입니다. ←→ 이런식으로.
벡터의 내적을 통해서 벡터간의 관계를 확인할 수 있었습니다. 우리가 통계시간에 배운 interaction term은 이것과 관련있습니다. (임의의 변수 a와 변수 b를 곱해 변수 ab를 만들어 interaction을 분석해 보셨을 것입니다... 사회과학에서 자주 사용하는 방법입니다)
3.6 Projection ★★
강의에서는 Shadow라는 표현을 사용해서 벡터끼리 투영되는 것을 설명하였습니다. 이는 하나의 벡터와 또 다른 벡터는 각도θ 만큼 벌어져 있는 삼각형 모양으로 되어 있다고 했을 때 두 벡터가 직교하지 않는 이상 하나의 벡터에서 다른 벡터로 내렸을 때 만나는 지점이 이 생깁니다. 그 지점으로 부터 처음의 벡터까지의 length를 projection이라고 부릅니다. 한국말로는 투영되었다고 하는데 투영投影이라 함은 '물체의 그림자를 어떤 물체 위에 비추는 일 또는 그 비친 그림자'를 의미합니다. 또 다른 말로는 투영投影이라고 하며 다른 공간에서 곧은 선을 쏜다는 의미도 가지고 있습니다. 보통 직각이 되도록 곧은 선을 투영합니다.
벡터의 내적(dot product)은 투영되는 벡터의 크기와 나머지 투영을 시작하는 벡터의 크기 곱하기 cosθ로 표현됩니다.
If \mathbf{r}r and \mathbf{s}s are perpendicular, the scalar projection is0.
In this case, cos(90^\circ) = 0cos(90∘)=0, hence the scalar projection is also 00.
그래서 두 벡터가 직교했을 때 서로 투영하는 부분이 전혀 없기 직각으로 선을 내렸을 때 겹치는 부분이 0이 됩니다. 이렇게도 설명할 수 있습니다. 아래의 판서는 앞의 내용들을 정리한 것이며 아래 |s|cosθ는 인접한 영역의 투영을 의미하는 것으로 벡터 s가 벡터 r에 얼마만큼 투영되는지를 보여주는 것입니다. 결과적으로 두 벡터 r, s의 내적(dot product)은 한 벡터와 그에 투영되는 다른 벡터에 대한 관계가 표현된다고 볼 수 있습니다.
한 벡터의 변화를 다른 벡터가 얼마만큼 설명할 수 있는가가 Projection의 핵심이다
Scalar projection
그리고 이는 역으로 투영되는 정도가 얼마나 되는지 볼 수 있다는 의미이기도 합니다. scalar projection으로 이를 계산할 수 있습니다. 두 벡터의 내적에서 한 벡터의 크기 만큼 나눠주면 인접하는 벡터의 투영 정도를 계산할 수 있습니다. 결과 값은 scalar(숫자)입니다.
☞ 투영되는 정도 = |s|cosθ = r.s / |r|
# Simple Python code for Scalar Projection
In [1]: import numpy as np
In [2]: r = np.array([3, -4, 0])
In [3]: s = np.array([10, 5, -6])
In [4]: np.dot(r, s) / np.sqrt(np.sum(np.square(r))) # r.s / |r|
Out[4]: 2.0
Vector projection
☞ r (r.s / |r| |r|)
# Simple Python code for Vector projection
In [1]: import numpy as np
In [2]: r = np.array([3, -4, 0])
In [3]: s = np.array([10, 5, -6])
In [4]: def size_of_vector(vector): # function for calculating length of vector
...: return np.sqrt(np.sum(np.square(vector)))
In [5]: (np.dot(r,s)/(size_of_vector(r)*size_of_vector(r)))*r # Calculation of r (r.s / |r| |r|)
Out[5]: array([ 1.2, -1.6, 0. ])
Summary of Projection
The scalar projection of a vector u onto a vector v is q ⋅ u, where q is the unit vector in the direction of v.
The vector projection of u onto v is the scalar projection of u onto v times q, where q is the unit vector in the direction of v.
The vector projection of u onto v is the best approximation of u in the direction of v, in the sense that the difference between u and its vector projection onto v is orthogonal to v.
The work done by a force that is applied at an angle to the displacement vector can be computed by projecting the force vector onto the displacement vector, and then multiplying the magnitudes of the force and displacement vectors.
Sample Quiz solving by python
|a|+|b|의 결과가 더 크게 나왔습니다. 우리가 피타고라스의 정리를 생각해보면 간단합니다. 빗변 c의 제곱은 양변 a와 b의 각 제곱을 합친 값과 같다는 사실을 떠올려보면 쉽게 이해가 될 것입니다. 이것을 "Triangle Inequality"라고 부르는데 삼각형을 만들기 위해서는 양변의 길이의 합이 빗변보다 길어야 삼각형을 만들 수 있다는 것을 의미합니다. 아래의 코드로 문제를 풀었습니다.
# Simple Python code for 'triangle inequality'
In [1]: import numpy as np
In [2]: def size_of_vector(vector):
...: return np.sqrt(np.sum(np.square(vector)))
In [3]: a = np.array([3, 0, 4])
In [4]: b = np.array([0, 5, 12])
In [5]: res1 = size_of_vector(a+b)
In [6]: res2 = size_of_vector(a) + size_of_vector(b)
In [7]: print(res1, res2)
17.0293863659 18.0
4. Changing basis (co-ordinate system)
딥러닝에서 많이 하는 것이 어떤 문제를 다른 고밀도의 벡터로 표현하는 방법이 많은데 수학적으로는 하나의 coordinate system에서 다른 coordinate system으로 바꾸는 것과 비슷하다고 합니다. 대부분의 머신러닝 문제가 이것과 상당히 밀접한 관련이 있습니다.
좌표계(coordinate system)
"숫자나 좌표를 이용해서 유클리디안 공간안에서 기하학적으로 문제를 표현하는 시스템"
앞에서 다루었던 projection product를 통해서 basis space에서 새로운 space로 데이터의 표현이 가능해진다고 합니다.
그리고 기저 벡터(basis vector)를 알아야 새롭운 벡터를 정의할 수 있다. 아래 그림을 보면 re라는 벡터는 청므의 기저벡터인 e1과 e2 벡터를 통해서 [3, 4]라는 새로운 벡터를 만들어 냈는데 여기서 새로운 기저 벡터 b1, b2를 사용해 rb라는 새로운 벡터를 만들어내었다. 기존의 re 벡터와 b1, b2 각 벡터와의 projection을 구하여 2b1, 0.5b2로 벡터 rb를 표현할 수 있었다.
다른 축을 사용해서 데이터를 새롭게 표현한 것이다. 이를 dot / projection product를 통해서 통해서 간단하게 해볼 수 있었다. 아래는 dot product가 깔끔하고 빠르게 되는 벡터의 직교(orthogonal) 사례입니다. 다르게 생각해보면 computation을 빠르게 하려면 벡터들을 직교로 만들어주는게 좋은데 기저변환(changing basis)을 통해서 직교 상태로 basis axis를 만들어 놓고 새롭게 벡터를 구할 수도 있습니다.
In [1]: import numpy as np
In [2]: def sov(vector): #size of vector
...: return np.sqrt(np.sum(np.square(vector)))
In [3]: re = np.array([3, 4])
In [4]: b2 = np.array([-2, 4])
In [5]: np.dot(re, b2) / np.square(sov(b2))
Out[5]: 0.4999999999999999
위의 코드는 re 벡터에 대해서 새로운 basis(기저)로 표현하고자 할때 그 projection을 구하는 문제였습니다. 결과는 0.5가 나왔고 b2에 대해서는 0.5 선형결합(;곱하기)을 해주면 re 벡터를 새로운 기저로 표현 가능합니다. 동일한 방식으로 계산했을 때 b1에 대해서는 2가 나왔습니다. 결과적으로 벡터 re는 기존의 e1, e2벡터에서 [3,4]로 표현됐으나 새로운 기저 b1, b2에서는 re = [2, 0.5] 로 새로운 기저에서 표현이 가능합니다.
In [1]: v = np.array([5, -1])
In [2]: b1 = np.array([1,1])
In [3]: b2 = np.array([1,-1])
In [11]: np.dot(v, b1) / np.square(sov(b1))
Out[4]: 1.9999999999999996 ## == 2
In [5]: np.dot(v, b2) / np.square(sov(b2))
Out[5]: 2.9999999999999996 ## == 3
### vb = [2, 3]
#귀찮아서 기저변환하는 함수를 만들었다.
In [6]: def sov(vector): #size of vector
...: return np.sqrt(np.sum(np.square(vector)))
In [7]: def change_basis(v, b1, b2):
...: vb1 = np.dot(v, b1) / np.square(sov(b1)) # vector projection 구하는 부분
...: vb2 = np.dot(v, b2) / np.square(sov(b2))
...: print(vb1, ',', vb2)
...: return np.array([vb1, vb2])
In [8]: v = np.array([10, -5])
In [9]: b1 = np.array([3, 4])
In [10]: b2 = np.array([4, -3])
In [11]: vb = change_basis(v, b1, b2)
### vb = [0.4 , 2.2]
5. Basis, Vector space, Linear independence
Basis is a set of n vectors that:
basis are not linear combinations of each other (linearly independent)
basis span the space
The space is then n-dimensional
만약 c1x1 + c2x2 와 같이 선형결합(linear combination) 조합으로도 0을 만들 수 없을 때 벡터 x1, x2는 독립이라고 말합니다. c1과 c2가 0아닌 조건아래일때.
벡터 b3가 벡터 b1과 벡터 b2에 대해서 선형적으로 독립적(linearly independent)이라고 하려면
b3 does not lie in the plane spanned by b1 and b2. b1과 b2의 선형결합과 같은 방식으로 확장된 다른 평면에 b3가 존재하면 안된다는 이야기입니다. 그리고 algebraic way로 표현했을 때 b3 != a1b1+a2b2이어야 합니다. 다른 차원(평면)에 존재해야 독립적이라고 할 수 있습니다.
예를 들어서,
a = [1, 1] , b1 = [2, 1], b2= [2, 2] 라는 벡터가 있다고 합시다. a를 span(넓혀서)해서 b1과 b2를 만들 수 있다면 a와 b1, b2 간에는 dependency가 있는 것입니다. b1은 a에서 scalar multiplication을 해도 만들기 어려워 보입니다. 반면에 b2는 a에 scalar 2를 곱하면 만들 수 있습니다. 따라서 b1은 독립적이고, b2는 종속적이라고 할 수 있습니다.
이런식으로 기존의 basis에서 span이 된다면 그 벡터는 linearly dependent하다고 볼 수 있습니다.
제가 정리한 내용들은 캐주얼한 설명이므로 조금 더 공학적으로 정확하게 이해하길 원하시는 분들은 여기 블로그에서 자세한 내용을 보시면 좋습니다.
6. Applications of changing basis = Changing reference frame
지금까지 dot product와 projection 그리고 basis와 change of basis(기저변환)에 대해서 다루었습니다. 이제 데이터 과학에서 왜 이러한 것들을 배워야 했는지 조금은 이해한 것 같습니다. 아래와 같이 X, Y 축에 데이터를 매핑하였다고 봅시다. 붉은 색 데이터 포인트들에 가장 잘 fit하는 선을 그리는 것이 일반적인 선형회귀의 문제입니다. 저 선으로부터 직교(orthogonal)하는 선을 그렸을 때 저 선으로부터 데이터까지 떨어지는 것은 noise 입니다. 저 noise를 가장 적게 하는 것이 데이터를 가장 올바르게 표현하는 방법이 될 것입니다. noise에 대한 정보가 모인 noise vector에 직교하는 선이되는 것입니다. 아래의 그림을 보면 위에서 우리가 보았던 형태의 직교하는 선이 추가로 그려졌고 이를 통해서 우리는 vector projection과 같은 방법으로 transformation이 가능합니다. 기존에 X-Y에 찍혔던 데이터를 새로운 선으로 표현할 수 있게 되는 것입니다.
머신러닝과 인공신경망을 이미 알고 있는 분들은 이미지를 분석할 때 이미지로 들어온 픽셀pixel 데이터가 새로운 basis에서 코나 피부 형태, 눈 사이의 거리 같은 것들을 묘사하기 위해 기존의 basis에서 바뀌는 것을 자주 보았을 것입니다. 우리가 보통 weight vector라고 말하는 vector에서 transformation이 일어나게 됩니다. 이 weight vector를 조정하기 위한 다른 vector space인 parameter function에 대한 space도 존재하게 됩니다. 자세한 건 앞으로 차차 다루도록 하겠습니다.
지금까지 배운 내용들은 하나의 공간에서 다른 공간으로 새롭게 데이터가 표현되는 것을 이해하기 위해서 선형대수(Linear Algebra)를 다루었습니다.
7. Matrices in Linear Algebra
머신러닝 또는 딥러닝에서 매트릭스는 vectors를 transform하기 위한 것으로서 많이 사용된다.
Linear Algebra is a mathematical system for manipulating vectors in the spaces described by vectors.
How matrices transform space
고등학교 때 배웠던 행렬연산으로 아래의 [[2, 3], [10, 1]] * [a b] 문제를 풀 수 있습니다. vector space를 transform한다는 관점에서는 조금 다르게 볼 수 있다. 앞에서 다루었던 basis를 관점으로 풀이해볼 수도 있다. 원래의 기저 벡터인 e1_hat = [1, 0], e2_hat = [0, 1] 두 기저벡터로부터 e1', e2'을 계산해볼 수 있다.
그 아래 [[2, 3], [10, 1]] * [3, 2]에서 [3, 2] 부분을 3*[1, 0] + 2*[0, 1]으로 볼 수 있고 이는 3*e1_hat, 2*e2_hat의 형태이다. 아래의 matrix multiplication을 통해 구한 결과는 기존의 기저에서 이동(transform)한 결과라고 볼 수 있는 것이다.
Types of matrix transformation
기존의 기저(basis)를 변경해서 새로운 기저로 표현하는 것이 matrix transformation이라고 볼 수 있는데
[ [1, 0], [0, 1] ] 의 행렬이 있다고 했을 때 1을 -1로 바꿔주면 matrix rotation이 발생하게 되고 matrix가 변하게 된다(transformation).
shears, stretches and inverses 등의 방식으로 matrix가 rotation되기도 하고 combination되기도 하면서 변화하게 된다.
transformation이라는 것이 다른 곳으로 매핑(mapping)한다고 봐도 되는데 coordinate system이 바뀌게 되는 것이다.
그중에서도 선형 변환(linear transformation)은 하나의 벡터 안에 있는 각 element를 다른 벡터의 각 element에 사상(mapping)하는 것이다.
행렬 변환(matrix transformation)은
shear : 고정된 방향으로 각 포인트를 그 방향과 평행한 라인에서 부호가 있는 거리에 비례하는 양만큼 이동시키는 선형 맵 (출처: 위키백과)
오늘은 기본적인 데이터의 종류에 대해서 알아보도록 하겠습니다. 데이터의 종류를 알아보는 것은 데이터 수집시 어떤 유형으로 수집하는 것이 좋은지를 설정하는 것부터 분석이나 시각화를 하는 것까지 데이터 유형에 따라 달라지므로 할 수 있는 것이 있고, 없는 것도 있습니다. 따라서 구분 할 수있는 것이 상당히 중요하겠죠?
데이터 분석과 시각화의 관점에서 봤을 때 중요한 데이터 유형은 크게 두가지로 나눌 수 있습니다.
크게는 범주형과 수치형으로 나뉘게 되고 세부적으로는 범주형은 명목형과 순서형, 수치형은 이산형과 연속형으로 나뉘게 됩니다. 개별로 한번 알아볼까요? 첫째, 명목형 데이터 (Nominal Data) 명목형 데이터는 Nominal 이라는 이름에서도 알 수 있듯 여러 카테고리들 중 하나의 이름에 데이터를 분류할 수 있을 때 사용됩니다.
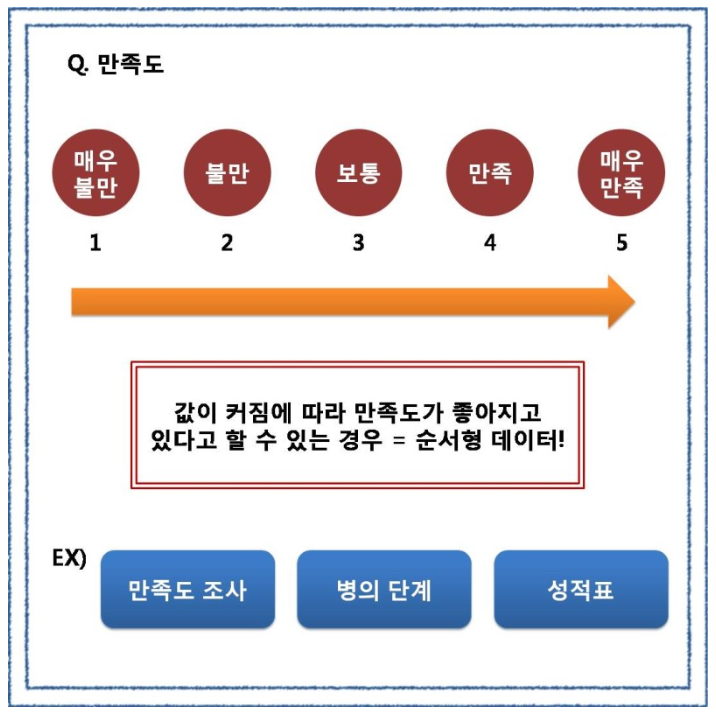
둘째, 순서형 데이터 (Ordinal Data) 순서형 데이터의 경우에는 말그대로 카테고리들이 순서가 있는 경우를 의미합니다.
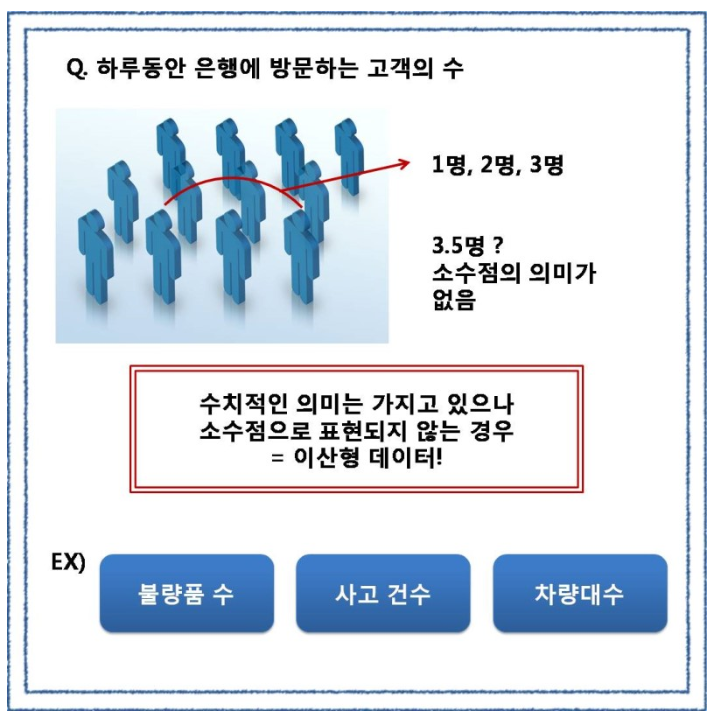
명목형 데이터와 같이 수를 세고 퍼센트로 표현할 수 있습니다. 리커트 척도는 5점 척도, 7점 척도 등을 통해 숫자로 표현되지 않는 것을 숫자로 표현해준다고 생각하시면 됩니다. 위의 예시 처럼 만족도를 5점 척도로 표현을 한다면 이는 리커트 척도를 이용한 것이죠, 특이하게도 리커트 척도는 등간격이라는 특징 때문에 연속적인 값을 가질 수 없더라도 평균을 구할 수 있습니다. 단, 주의하셔야 할 점은 이때 구해지는 평균이라는 숫자는 수학적인 의미가 있는 것이 아닙니다.5점 척도를 이용하여 조사를 하고 구한 평균이 4.1 이라면 대다수의 사람들이 만족하고 있다고 볼 수 있다는 것입니다. 셋째, 이산형 데이터 (Discrete Data) 이산형 데이터는 수치적인 의미를 가지나 소수점의 형태로 표현되지 못하는 데이터를 의미합니다.
이산형 데이터의 표현방법으로는 앞선 데이터와 동일하게 퍼센트로 표현하며, 예를들어 불량품 수라고 한다면 '양산되는 제품들 중 불량률이 5%다.' 라고 할 수 있습니다.
넷째, 연속형 데이터 (Continuous Data) 연속형 데이터는 수치적인 의미를 가지고 소주점으로 표현이 가능하며, 측정할 수 있는 데이터를 의미합니다.
연속형 데이터의 경우에는 평균과 표준편차, 분산으로 표현하고 추가적으로 퍼센트로도 표현이 가능합니다. 예를들어 키를 보면 160, 170, 180의 사람이 있다면 평균은 170, 표준편차는 10이 됩니다. 이를 퍼센트로 하면 160~169, 170~179, 180~189 총 3개의 구간으로 나눠서 봤을 때 수를 세면 각 구간별로 하나씩 나옵니다. 따라서 퍼센트로 따지면 33.3%가 되는 것입니다.
예를들어 나이를 본다면, 여러가지의 데이터 형태로 구분지을 수 있습니다. 먼저 나이 그자체를 보면 우리는 시간의 흐름에 따라 나이를 자연스럽게 먹고 있기 때문에 연속형 데이터라고 할 수 있습니다. 하지만 20살~29살 까지인 사람들의 수를 센다면 이산형 데이터가 될 수 있겠죠. 그리고 설문조사시연령을 묻는 문항에서 ① 10대 ② 20대 ③ 30대 ④ 40대 ⑤ 50대 이상 으로 데이터를 수집했다면 이는 순서형 데이터가 된다는 것이죠. 이처럼 동일하게 나이를 나타내는 데이터를 어떻게 수집하느냐에 따라서 데이터 유형이 달라집니다. 그리고 데이터 분석 방법도 달라지겠죠. 그러므로 데이터를 구분할 줄 아는 것이 중요합니다.











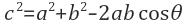















{kind=link}