반응형
출처:http://blog.seulgi.kim/2014/04/log-aggregator-scribe-flume-fluentd.html
https://docs.google.com/presentation/d/12A5RlMCVDN6tA_zUnLrZ0TN5v08gz2GhlRdzxy3T3mU/edit?usp=sharing
회사에서 최근에 Log aggregator system으로 무엇을 사용해야 할지 조사해본 자료다.
우선 log aggregator가 무엇인지 한 문장으로 설명하면, 여러 머신에서 쌓인 로그들을 한 번에 분석할 수 있도록 수집하여 주는 시스템을 말한다.
요새는 특히나 클라우드 시스템이 유행하면서 같은 일을 하는 시스템임에도 다른 머신에서 돌아가는 일이 많아지면서 필요성이 크게 증가하였다.
이번 조사로 알게 된 것들을 적어보도록 하겠다.
Scribe
우선 scribe는 Facebook에서 제작하고 사용하던 log aggregator system이다.
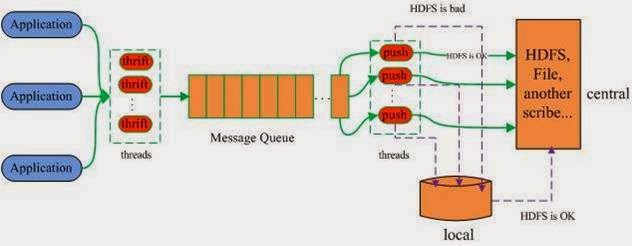 |
| scribe: http://www.cnblogs.com/brucewoo/archive/2011/12/13/2285482.html |
Scribe는 일종의 message queue와 message queue에 쌓인 message를 DB에 저장해 주거나, DB가 실패하였으면 local에 저장하였다가 DB가 복구되었을 때 다시 DB에 저장해 주는 것만을 책임진다. 다시 말하면, message queue에 실제로 메시지를 보내는 부분은 사용자가 직접 작성하여야 한다는 것이다.
흔히들 말하는 scribe의 장점은 c++로 만든 만큼 다른 시스템들의 3~5배 정도의 성능을 보여준다는 것이다. 하지만 실제 scribe 사용자들은 무엇보다도 Facebook이 실제로 사용하였던 솔루션인 만큼 성능과 안정성에서 신뢰도가 있다는 것을 장점으로 뽑는다.
하지만 나는 scribe를 사용하는 것을 추천하지는 않는다.
일단 가장 큰 문제는 더이상 Facebook이 Scribe를 사용하지 않는다는 것이다. Facebook은 이미 Java로 작성한 Calligraphus를 사용하기 시작했다. scribe는 open source이고 개발이 완전히 멈춘 것은 아니다. 하지만 Facebook이 중심적으로 만들던 시절에 비하면 거의 발전이 없는 상태라고 해도 될 정도이다.
앞에서 말했듯이 Scribe는 message를 보내는 부분을 완전히 새롭게 작성해야 한다. 또한, 바이너리 배포를 안하기 때문에 사용하려면 Scribe 자체도 빌드하여야 하는데 Scribe 자체가 여러 라이브러리에 의존성이 걸려있기 때문에 빌드하는 것도 쉽지 않다.
남은 장점은 성능밖에 없는 관계로 일단 다른 솔루션을 사용해보고, 그것으로 감당이 되지 않을 정도로 많은 부하가 걸리는 게 아니라면 굳이 Scribe를 사용할 이유는 없어 보인다.
Flume
다음으로 소개할 Flume은 과거 Cloudera에서 제작하여 지금은 apache의 top level project가 되었다.
Flume의 가작 큰 특징(?)은 중간에 설계가 크게 바뀌었다는 것이다.
Flume의 가작 큰 특징(?)은 중간에 설계가 크게 바뀌었다는 것이다.
 |
| Flume OG: http://archive.cloudera.com/cdh/3/flume/UserGuide/ |
 | |
|
원래의 Flume OG는 master가 존재하여 agent나 collector를 master를 통해서 제어해야 했다. 하지만 Flume NG에서는 각각의 Agent가 독립적으로 어디로 data를 보낼지 결정할 수 있다.
Flume은 deb package로 배포하고 있기 때문에 사용하기 쉽다는 장점이 있지만, plugin을 만들기 쉬운 구조가 아니므로 주어진 조건에 맞게 사용하는 것 외에는 힘들다는 단점이 있다. 아직은 Flume을 검색하면 Flume OG 시절의 문서와 사용 방법이 나오는 경우가 있다는 것도 단점이다.
Flume은 deb package로 배포하고 있기 때문에 사용하기 쉽다는 장점이 있지만, plugin을 만들기 쉬운 구조가 아니므로 주어진 조건에 맞게 사용하는 것 외에는 힘들다는 단점이 있다. 아직은 Flume을 검색하면 Flume OG 시절의 문서와 사용 방법이 나오는 경우가 있다는 것도 단점이다.
Fluentd
Fluentd는 ruby와 c로 짜여진 log aggregator 시스템이다.
 |
| fluentd: http://blog.treasure-data.com/post/13047440992/fluentd-the-missing-log-collector-software |
기본적인 구조는 Flume NG와 비슷한 구조로 되어 있다. Flume의 Source, Channel, Sink가 각각 Input, Buffer, Output이 되었다고 보면 된다.
Fluentd의 가장 큰 특징이자 장점은 각 파트별로 plugin을 만들기 쉽다는 것이다. 직접 plugin을 만들지 않더라도, ruby로 짜여 있으며 plugin을 gem으로 배포하기 때문에 plugin을 쉽게 붙일 수 있다는 것도 큰 장점이다.
Fluentd의 가장 큰 특징이자 장점은 각 파트별로 plugin을 만들기 쉽다는 것이다. 직접 plugin을 만들지 않더라도, ruby로 짜여 있으며 plugin을 gem으로 배포하기 때문에 plugin을 쉽게 붙일 수 있다는 것도 큰 장점이다.
그러면서도 성능이 필요한 부분은 c로 작성하여 ruby로 wrapping을 하였기 때문에 성능이 크게 떨어지지도 않는다.
물론 Fluentd도 단점이 있다.
중요한 부분은 c로 짜여 있다고 해도 대부분의 부분이 scribe보다는 느리다.
대부분이 ruby로 짜여 만큼 ruby의 고질적인 문제인 memory fragmentation을 피할 수 없다.
로그에 시간을 반드시 남기게 되어 있기 때문에 agent들 사이에 시간이 맞지 않으면 log가 이상하게 쌓이기도 한다.
하지만 이런 문제들은 전부 어렵지 않게 해결할 방법이 있다.
scribe보다 느리다고 했지만, 대부분 시스템에서 사용하기에는 충분하다. 그래도 느리다면 멀티코어를 이용하는 플러그인을 사용하면 된다.
memory fragmentation은 jemalloc을 사용하면 된다.
시간이 맞지 않는 문제는 클라이언트들에서 ntpd를 돌리면 해결된다.
사용하기 쉽고, 단점들을 해결하기도 쉽기 때문에 아마 Fluentd를 사용하게 될 것 같다.
물론 Fluentd도 단점이 있다.
중요한 부분은 c로 짜여 있다고 해도 대부분의 부분이 scribe보다는 느리다.
대부분이 ruby로 짜여 만큼 ruby의 고질적인 문제인 memory fragmentation을 피할 수 없다.
로그에 시간을 반드시 남기게 되어 있기 때문에 agent들 사이에 시간이 맞지 않으면 log가 이상하게 쌓이기도 한다.
하지만 이런 문제들은 전부 어렵지 않게 해결할 방법이 있다.
scribe보다 느리다고 했지만, 대부분 시스템에서 사용하기에는 충분하다. 그래도 느리다면 멀티코어를 이용하는 플러그인을 사용하면 된다.
memory fragmentation은 jemalloc을 사용하면 된다.
시간이 맞지 않는 문제는 클라이언트들에서 ntpd를 돌리면 해결된다.
사용하기 쉽고, 단점들을 해결하기도 쉽기 때문에 아마 Fluentd를 사용하게 될 것 같다.
logstash
logstash는 다른 것들과는 약간 다른 관점에서 조사하다가 나온 것이다.
로그를 수집하였다고 하더라도 수집된 로그를 분석하여 보기좋게 표현할 방법이 없으면 그건 그저 information이 되지 못한 단순한 data일 뿐이다.
logstash는 elsaticsearch family의 하나가 되면서 쌓인 로그를 웹으로 보여주는데 좋은 툴인 kibana와 함께 쓸 수 있어서 손쉽게 로그를 보고 분석할 수 있는 기능을 제공해준다.
하지만 fluentd도 kibana를 붙일 수 있고, logstash자체의 기능이 fleuntd보다 못하기 때문에 굳이 logstash를 쓸 일은 없어 보인다.
로그를 수집하였다고 하더라도 수집된 로그를 분석하여 보기좋게 표현할 방법이 없으면 그건 그저 information이 되지 못한 단순한 data일 뿐이다.
logstash는 elsaticsearch family의 하나가 되면서 쌓인 로그를 웹으로 보여주는데 좋은 툴인 kibana와 함께 쓸 수 있어서 손쉽게 로그를 보고 분석할 수 있는 기능을 제공해준다.
하지만 fluentd도 kibana를 붙일 수 있고, logstash자체의 기능이 fleuntd보다 못하기 때문에 굳이 logstash를 쓸 일은 없어 보인다.
반응형
'프로젝트 관련 조사 > 로그 관련' 카테고리의 다른 글
| syslog 실무가이드 (0) | 2015.09.24 |
|---|---|
| 아마존( Amazon ) AWS 윈도우( Window )에서 접속 - Putty , pem ppk 변환 (0) | 2015.09.24 |
| syslog (0) | 2015.09.21 |
| 로깅 소스 분류 (0) | 2015.09.21 |
| Flume 설계 (0) | 2015.09.11 |