반응형
위에서 언급한 수집기 오픈 소스중 3가지 Flume, Scribe, Chukwa를 간단 비교요약하면 아래와 같다.
| Apache Flume | Facebook Scribe | Apache Chukwa | |
| Overview | 대용량의 로그 데이터를 분산,안정성,가용성을 바탕으로 효율적으로 수집,집계,이동이 가능한 로그수집 솔루션 | Facebook이 개발하여 오픈소스화한 로그수집서버. 대량의 서버로 부터 실시간으로 스트리밍 로그 수집을 위한 솔루션 | Apache Hadoop의 서브 프로젝트로 분산되어 있는 서버에서 로그 데이터를 수집, 저장, 분석하기 위한 솔루션 |
| Home | http://flume.apache.org/ | https://github.com/facebook/scribe | http://chukwa.apache.org/ |
| Last Version | 1.4.0 (2013.7.2) | 2.2(2010) | 0.5.0 (2012.1.26) |
| Status | Cloudera -> Apache Top-Level Project | Facebook -> Open Source | Yahoo -> Apache Incubator project |
| WIKI | https://cwiki.apache.org/confluence/display/FLUME/Home | https://github.com/facebook/scribe/wiki | http://wiki.apache.org/hadoop/Chukwa/ |
| Document | 풍부 | 빈약 | 풍부 |
| Implementation | Java | C++ | Java |
| Community | 활발 | 활발 | 보통 |
| Summary |
|
|
|
| Outline | 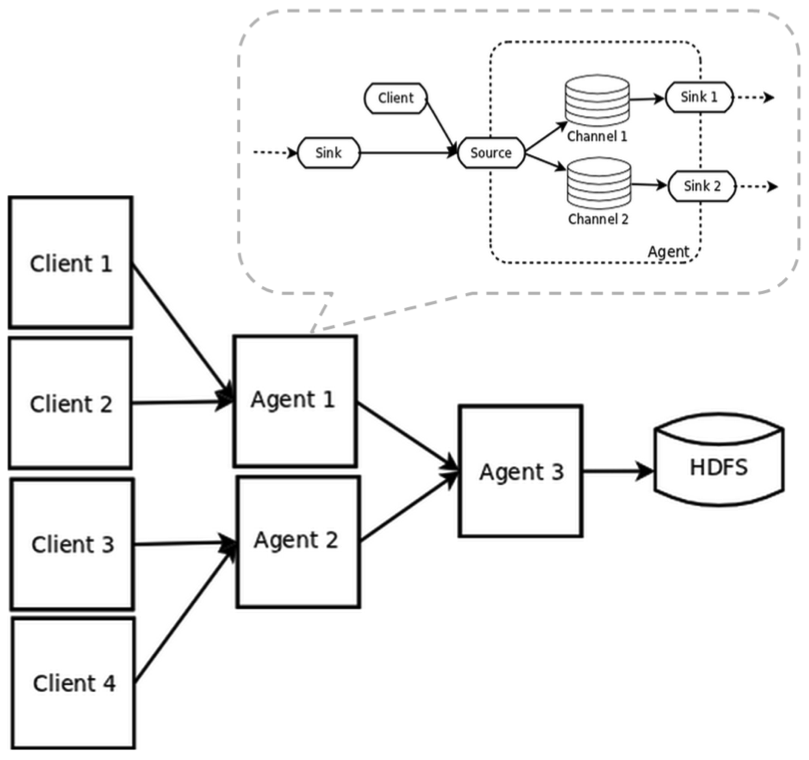 |
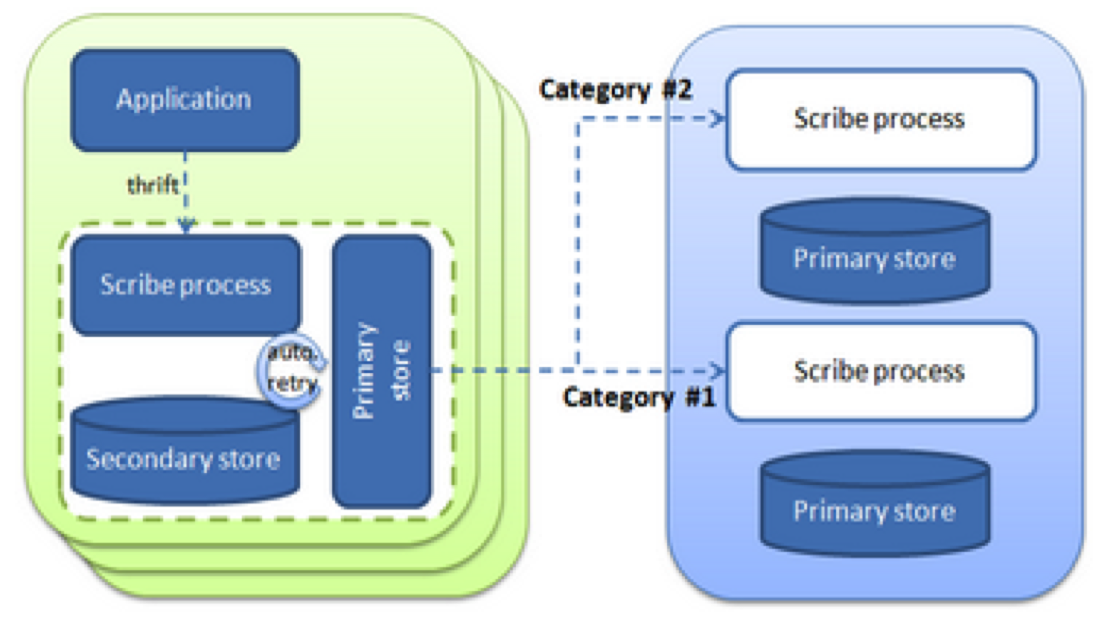 |
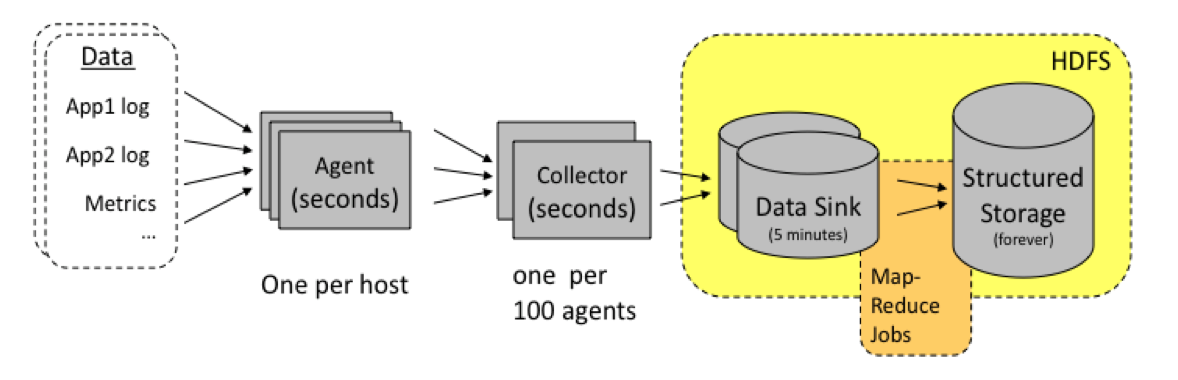 |
반응형
'프로젝트 관련 조사 > 로그 관련' 카테고리의 다른 글
| flume 설치 및 예제 (2) | 2015.09.09 |
|---|---|
| flume windows install (0) | 2015.09.07 |
| flume 관련 내용 (0) | 2015.09.07 |
| java install (0) | 2015.09.07 |
| Flume (0) | 2015.09.01 |
