이번 포스팅의 주제는 텐서플로우나 케라스 등을 사용해서 모델을 만들어 보았으면 다들 아실 용어인 epoch와 batch size 그리고 iteration입니다.
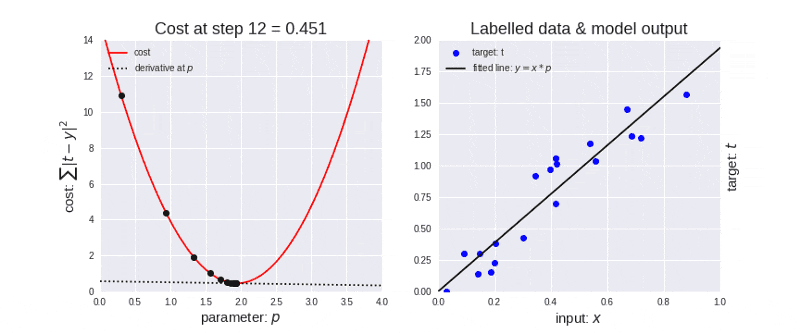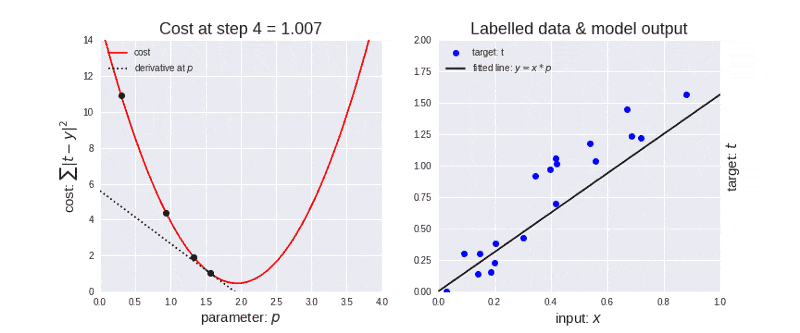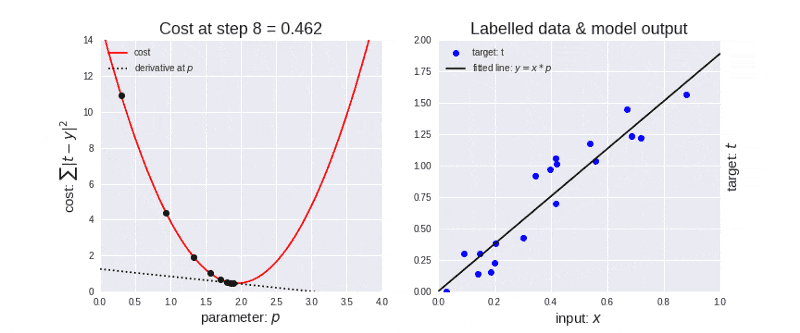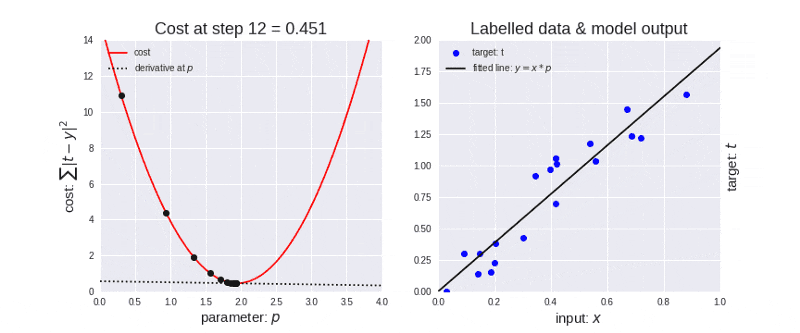
▶ 알고리즘이 iterative 하다는 것: gradient descent와 같이 결과를 내기 위해서 여러 번의 최적화 과정을 거쳐야 되는 알고리즘
optimization 과정
▶ 다루어야 할 데이터가 너무 많기도 하고(메모리가 부족하기도 하고) 한 번의 계산으로 최적화된 값을 찾는 것은 힘듭니다. 따라서, 머신 러닝에서 최적화(optimization)를 할 때는 일반적으로 여러 번 학습 과정을 거칩니다. 또한, 한 번의 학습 과정 역시 사용하는 데이터를 나누는 방식으로 세분화 시킵니다.
이때, epoch, batch size, iteration라는 개념이 필요합니다.
- epoch
One Epoch is when an ENTIRE dataset is passed forward and backward through the neural network only ONCE
(한 번의 epoch는 인공 신경망에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것을 말함. 즉, 전체 데이터 셋에 대해 한 번 학습을 완료한 상태)
▶ 신경망에서 사용되는 역전파 알고리즘(backpropagation algorithm)은 파라미터를 사용하여 입력부터 출력까지의 각 계층의 weight를 계산하는 과정을 거치는 순방향 패스(forward pass), forward pass를 반대로 거슬러 올라가며 다시 한 번 계산 과정을 거처 기존의 weight를 수정하는 역방향 패스(backward pass)로 나뉩니다. 이 전체 데이터 셋에 대해 해당 과정(forward pass + backward pass)이 완료되면 한 번의 epoch가 진행됐다고 볼 수 있습니다.
역전파 알고리즘이 무엇인지 잘 모른다고 하더라도 epoch를 전체 데이터 셋에 대해 한 번의 학습 과정이 완료됐다고 단편적으로 이해하셔도 모델을 학습 시키는 데는 무리가 없습니다.
epochs = 40이라면 전체 데이터를 40번 사용해서 학습을 거치는 것입니다.
▶ 우리는 모델을 만들 때 적절한 epoch 값을 설정해야만 underfitting과 overfitting을 방지할 수 있습니다.
epoch 값이 너무 작다면 underfitting이 너무 크다면 overfitting이 발생할 확률이 높은 것이죠.
- batch size
Total number of training examples present in a single batch.
- iteration
The number of passes to complete one epoch.
batch size는 한 번의 batch마다 주는 데이터 샘플의 size. 여기서 batch(보통 mini-batch라고 표현)는 나눠진 데이터 셋을 뜻하며 iteration는 epoch를 나누어서 실행하는 횟수라고 생각하면 됨.
▶ 메모리의 한계와 속도 저하 때문에 대부분의 경우에는 한 번의 epoch에서 모든 데이터를 한꺼번에 집어넣을 수는 없습니다. 그래서 데이터를 나누어서 주게 되는데 이때 몇 번 나누어서 주는가를 iteration, 각 iteration마다 주는 데이터 사이즈를 batch size라고 합니다.
딥러닝 라이브러리들에서 GPU 가속을 사용하기 위해서는 앞서 말했던 것과 같이 CUDA와 여러 GPU 관련 라이브러리를잘잡아줘야 한다. 하지만 이 작업이 생각보다 귀찮은 것은 차치하더라도, Tensorflow나 PyTorch가 (특히 TF가..!!!) 요구하는 CUDA/cuDNN을 버전 세트를 맞춰주는 것도 한세월.
하지만 최근 몇년 사이 딥러닝을 위한 도커 이미지가 넘쳐나고 있다.
당장 Tensorflow나 PyTorch의 공식 이미지부터 시작해 deepo, h2o.ai등 굉장히 다양한 이미지들이 넘쳐나고 있다. 이들을 이용해 추가적인 라이브러리를 설치해 입맛에 맞는 도커 이미지를 만들면 가장 편안하게 연구 개발을 할 수 있다.
Deepo 이미지로 띄우기
여러가지를 사용해 보았지만 현재(2019.11.27)시점 체감상 가장 안정적이고 잘 동작하고 나름 설정이 잘 되어있는 - 혹은 개인적 취향에 맞는 - 라이브러리는 바로deepo였다.
도커 이미지 실행시 어떤 GPU를 사용할지 지정해야 하는데,--gpus=all로 사용할 경우 해당 시스템에 있는 모든 GPU를 사용하도록 지정하고,-gpus '"device=1,2"'와 같이 지정시 PCIe Bus기준 1,2번에 해당하는 것만 사용하도록 지정할 수 있다.
2) 도커 이미지로 연결할 포트 지정
-p명령어를 통해 어떤외부포트를 어떤내부포트로 연결할지 지정할 수 있다.
위와같이-p 18888:8888로 지정할 경우해당컴퓨터IP:18888로 접속시 Jupyter Notebook 포트인 내부 8888에 접근할 수 있게 된다.
3) 유저명으로 접근
위와 같이 사용시 현재컴퓨터에 로그인한 유저의 ID와 Group ID를 알 수 있다.
만약 첫 유저라면 보통은 1000:1000 속성을 가지게 된다.
앞서 Dockerfile에서 지정했던 유저는 1000번이기 때문에 만약 혼자 사용하는 컴퓨터라면 유저 권한을 맞춰줄 수 있다.
만약 여럿이서 사용하는 서버라면 Dockerfile 빌드시 유저 id를 다르게 생성하면 된다.
4) 로컬의 임의의 폴더(.dockervm)을 연결
위와 같이 임의의 폴더에 도커 내부의 폴더와 연결하면,pip install --user와 같은 명령어를 통해 설치한 패키지는 도커 이미지를 재시작 할 경우에도 여전히 설치된 상태를 유지할 수 있고, JupyterNotebook의 패스워드 역시 매번 새로운 토큰 대신 고정된 패스워드를 사용할 수 있다.
또한 로컬의 code 폴더와 내부의 code 폴더를 맞춰 쉽게 액세스 할 수 있도록 실제 작업환경 공간을 맞춰준다.
5) 로컬의 유저 폴더를 내부에 ReadOnly로 연결
Docker의 Volume Mount시:ro옵션을 붙이면 ReadOnly 모드로 동작한다. 특정 파일들을 접근할 때 매번 도커 이미지 내에 업로드 하는 대신, 로컬의 파일을 손쉽게 가져다 쓸 수 있도록 만들어 준다.
6) ZSH를 이용한 JupyterNotebook 실행
마지막 단계인 도커 이미지 실행 단계이다.
단순하게jupyter notebook이라고 실행하면 문제가 발생한다.PATH지정이 되지 않아 앞서 설치한 패키지가 인식되지 않을 수 있기 때문이다.
따라서PATH를 오버라이딩해줘 Python이 인식하도록 만들어줄 수 있다.
이후 No browser(CLI인 경우) 옵션, 그리고 모든 hostname을 통해 접근 가능하도록0.0.0.0으로 지정하고, JupyterNotebook이 실행될 기본 폴더를/code로 지정해주면 끝이 난다.
정리
딥러닝, 혹은 자연어 처리 등을 위해 Docker 이미지를 직접 만들어서 쓰는건 사실 당연한 일이다. 아무리 기존의 딥러닝 이미지들이 잘 되어있다고 하더라도 특히 한국어를 위한 이미지는 많이 부족한 것이 사실이다.
시스템을 많이 건드리지 않으면서도 커스터마이징을 좀 더 쉽고 빠른 연구가 가능하도록 자신만의 환경을 쌓아가는 것도 중요한 부분이지 않을까 생각해 본다.
개인 데스크탑에서 cuda나 cudnn 등 nvidia 가속을 이용하는 환경을 구축하는 게 간단하지는 않습니다. 저의 경우 파이선 가성화를 위해서 anaconda를 주로 사용하는데, conda 업그레이드시 함께 포함된 패키지가 업데이트되면서 호환성이 깨지는 경우가 종종 발생하였습니다.
그래서, 차라리 누군가 잘 만들어놓은 도커를 가져다가 조금만 변경해서 사용하면 좋겠다는 생각에서 저의 개인적인 경험을 바탕으로 소개하도록 하겠습니다.
Deepo 도커 소개
deepo는 딥러닝/머신러닝 개발 환경을 쉽게 구축할 수 있는 all-in-one 도커입니다. 자세한 것은 이 링크를 눌러deepo깃헙 페이지를 방문하면 알 수 있습니다.
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE ... ufoym/deepo all-py36-cu101 5d5a5c342dbf 2 weeks ago 13.3GB ufoym/deepo latest 5d5a5c342dbf 2 weeks ago 13.3GB ...
저는 2개의 별도 버전을 설치했는데, 동일한 것으로 보이네요.
이것으로 설치완료입니다. 이제부터 사용하기만 하면 됩니다. 다만, 도커에 익숙하지 않은 분들을 위해서 몇 가지 더 설명해봅니다.
Docker 실행하기
아래는 deepo 도커를 실행하고 bash로 진입하는 명령어입니다.
$ docker run -p 8888:8888 --gpus all -it -v {host-dir}:{container-dir} ufoym/deepo bash
도커 옵션 설명:
run: 도커 실행 명령어
"-p 8888:8888": 컨테이너의 8888번 포트를 호스트 OS 8888번 포트로 포워드하는 옵션입니다. 나중에 jupyter notebook이나 lab에서 사용하는 8888번 포트를 외부에서도 접속이 가능해집니다.
"--gpus all": 컨테이너의 gpu 사용을 가능하도록 하는 옵션입니다.
"-it": 인터랙티브 터미널을 사용하기 위한 옵션입니다.
"-v {host-dir}:{container-dir}": 호스트의 디렉토리를 컨테이너 내부에 공유하기 위한 옵션입니다.
"bash": 터미널에서 실행할 명령어입니다. bash 쉘을 통해 도커에 진입하게 됩니다.
Jupyter Lab 설치하기
저는 Jupyter Notebook 보다는 Jupyter Lab을 선호하는데 Deepo에는 안타깝게도 Jupyter Notebook만 설치되어 있습니다. Jupyter Lab을 설치하겠습니다. 컨테이너 내부에서 설치한다고 가정합니다.
포트는 아까 실행할때 지정한 8888번 포트로 띄웁니다. 그러면, 이제 호스트 OS의 8888번 포트를 열어두기만 하면 외부에서도 접근이 가능해집니다. 그리고 컨테이너 내부에서 root로 실행시키고 있기 때문에, --allow-root 옵션이 필요하고 브라우저가 없기 때문에 --no-browser 옵션도 같이 붙여 실행합니다.
Deepo에 변경사항 저장하기
필요에 따라서 Jupyter Lab 등 별도의 라이브러리나 프레임워크를 설치하는 경우에는 도커를 실행할 때마다 리셋되기 때문에 재설치의 번거로움이 있습니다. 이런 경우 변경사항을 저장해서 내가 원하는 최적의 환경을 구축할 수 있습니다.
$ docker commit {container-id}{new-image-name}
위 명령어를 실행하면 현재 실행중인 컨테이너의 상태를 저장하여 새로운 도커 이미지로 생성합니다.
$ docker commit f7e19aaeef3f deepo_jupyterlab
을 실행하고 이미지를 확인해보겠습니다.
$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE deepo_jupyterlab latest 19ea1eeb6d17 2 hours ago 13.3GB ufoym/deepo all-py36-cu101 5d5a5c342dbf 2 weeks ago 13.3GB ufoym/deepo latest 5d5a5c342dbf 2 weeks ago 13.3GB
위와 같이 새롭게 생성한 도커 이미지를 실행하면 jupyter lab이 설치된 나만의 이미지를 실행할 수 있게 됩니다.








{kind=link}
{kind=link}
{kind=link}